
- Published on
Working with APIs - Pagination
- Authors
- Name
- Amit Barletz
- @BarletzA52


Making Paginating Requests from APIs with REST API and GraphQL
Pagination is a pattern that helps deal with requests from big databases. It solves excessive network traffic by returning small chunks of data instead of whole databases.
Part 1 - Paginated APIs
Whether you are building your API or consuming another API, the API needs to provide a mechanism to paginate the list of resources. Without pagination, a simple search could return millions or even billions of hits, causing excessive network traffic (unless the data volume is pretty small, fixed, and well-defined).
In both cases, as a consumer of the API or as the builder, we should be aware of 3 parameters:
- Is the dataset sortable -can it be ordered by some unique ID or creation date.
- Is the dataset filterable - which filter params should be accepted.
- Does the request contain queries - for REST params and GraphQL query name.
There are different pagination techniques when it comes to listing of provided endpoints:
1. Page-Based pagination (offset-based pagination):
In this technique, the dataset is divided into pages and the endpoint accepts:
- LIMIT - represents the length of the list of the data per page,
- OFFSET - the starting position in the list of items (how many items to skip).
REST Implementation:
A page-based REST API request will look like this:
GET /api/items?limit=50&offset=100
A page-based SQL query will look like this:
SELECT * FROM Items ORDER BY item_id ASC LIMIT 50 OFFSET 100
Our server code will set a limit of 50, so we will get a list of 50 objects. In addition, it will set the offset to 100, which effectively means: “get me the 3rd page’s data” or “get me the data from 101 to 150”.
If we want to get the most recent 25 items, the request from the client would look like this:
GET /api/items?limit=25
This will result in an SQL request without an offset:
SELECT * FROM Items ORDER BY item_id ASC LIMIT 25
GraphQL Implementation:
In GraphQL, we build a query that calls the items (like in the URL we call to /api/items) with the variables offset and limit and pull out our desired data.
{
items(offset: 100, limit: 50) {
id
name
descrioption
category {
id
name
}
}
}
Of course, we don't always want only the third page, right?
So, to make a generic query, we can build a query named getItems. This query accepts two variables: limit and passes them to items as the values. This way, we can call getItems query with different values, these values are passed to items, and we get our desired result.
getItems($offset: Int!, $limit: Int) {
items(offset: $offset, limit: $limit) {
id
name
descrioption
category {
id
name
}
}
}
Pros and Cons of Page-based pagination:
👍 Pros:
- Support skip to a specific page (offset).
- Allows sending parallel requests with different pages.
- Easy to implement.
👎 Cons:
- Can return duplicated data:
- First request asks for page 1, and if a new record is inserted to the first page during the processing of the request, then the request with page 2 will have a record repeated which was returned on the previous request.
- Can miss data:
GET /api/items?limit=15&offset=0
- 10 new items are added to the DB
GET /api/items?limit=15&offset=15
- The second request will only return 5 items, as adding 10 new items moved the offset back by 10 items. To fix this, the client would need to offset by 25 for the second query GET /items?offset=25&limit=15, but the client could not possibly know other objects being inserted into the table.
- Bad performance for large offsets.
2. Cursor-Based pagination:
A cursor is a piece of data that contains a pointer to an element, and the information to get the next/previous element.
The cursor can be provided (or not) in different ways:
- It might be opaque, so that users couldn't manipulate it.
- It might be returned once per every element so that clients can ask for an element after a specific one.
- It might be returned as a part of the payload / part of the headers.
- It might contain all the information needed, or partially and allow clients to add filter params.
For the very first request, the cursor is null and the request returns with a cursor that points to the first element of the second page (batch of data).
Let's take for example the following requests:
First request:
GET /api/posts?limit=20
The server responds by returning the requested items and the next cursor.
{
info: {
cursor: 123456789
limit: 20
}
posts: [ ... ]
}
The client receives the data with some meta data inside the info property. The cursor here is a timestamp. It might be the creation date of the data or its update date - or the time this item was added to our shop’s stock. Then the client request uses this cursor to get the next batch of data.
REST Implementation
GET /api/posts?limit=20&nextCursor=123456789
The SQL query will depend on the implementation, but in most cases, it uses WHERE condition.
SELECT * FROM posts
WHERE created_timestamp < 123456789
ORDER BY created_timestamp
LIMIT 20
NOTE: limit can also be called count (20), and cursor can also be called after (timestamp)
SELECT * FROM posts
WHERE created_at < $after
ORDER BY created_timestamp
LIMIT $page_size
GraphQL Implementation
In GraphQL, we can take a similar approach, but we need to specify all the fields we want to get back
{
posts(cursor: 123456789, count: 20) {
info {
cursor
limit
}
title,
subTitile
description
category {
name
}
}
}
Pros and Cons of Cursor-based pagination:
👍 Pros:
- Much faster than page-base pagination.
- Consistent results - there are no issues such as duplication of the data.

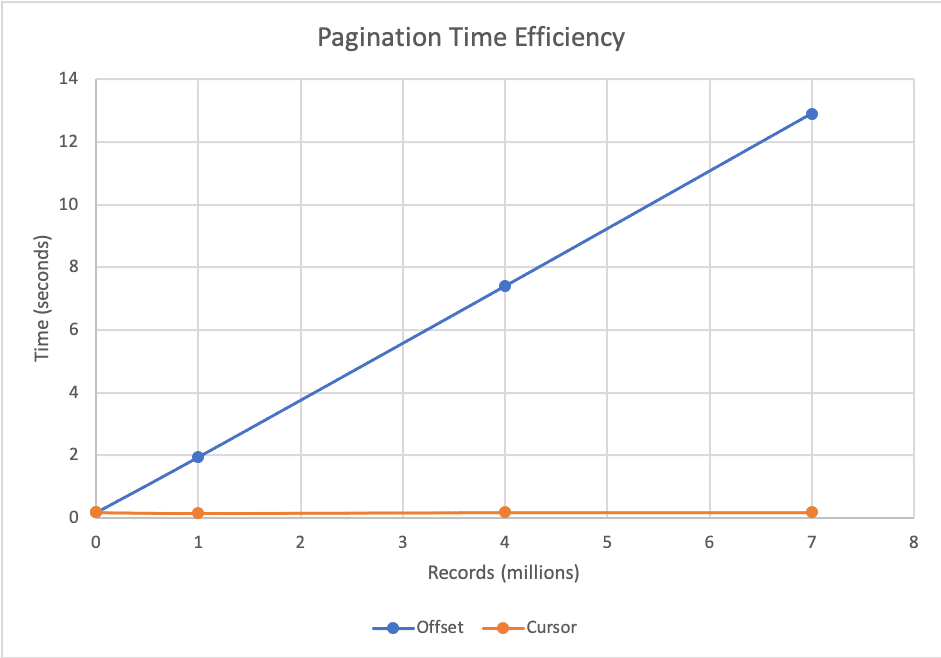
👎 Cons
- There is no way to skip pages.
- We can't send parallel request because we must wait for the next cursor.
- Compared to page-based, it has a more complex implementation as seen in the SQL query.
If you are using any website that deals with real-time data (lots of data), like Facebook, Slack, Twitter, etc. you are likely seeing cursor pagination in action. Cursor pagination is the preferred backed method for delivering an infinite scroll on the frontend.
3. Numbered-Page Pagination:
A very easy-to-implement pagination technique, thought it's often less useful for modern apps compared the alternative pagination models.
REST implementation:
A numbered-page-based REST API request will look like:
GET /api/items?page=2
A numbered-page-based SQL query will look like this:
SELECT * FROM Items ORDER BY created_at LIMIT 10 OFFSET 20;
We can see that we want to get the second page, and we know (because we've already investigated the API response) that for every request we get 10 items, therefore, the offset should be 20, as we want to start *after item 20.
GraphQL implementation:
The query should look like this:
{
items(page: 2) {
id
itemName,
description
category {
id
categoryName
}
}
Pros and Cons of Numbered-page-based pagination:
👍 Pros:
- Easy to implement (and easy to add a skip and limit to a query)
👎 Cons:
- Might cause skipping an item.
- Might cause duplications - display the same item twice
The following two techniques are less used in the industry, both in GraphQL and in REST

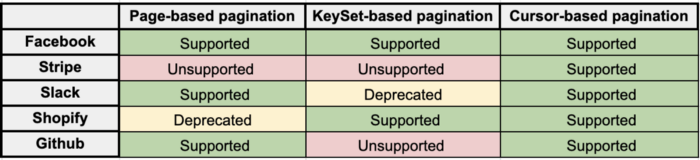
4. KeySet-Based pagination:
The API provides a key param that acts as a filter value and should be the same key of the keyset sorted by order (if the set is sorted by created_at, then the key param should be since_created_at). Actually, it is like a cursor, but more specialized one.
The first request doesn’t contain the filter param. The response of this request will contain the value of the key for the last element of the set (if the filter is created_at, to get the next page, the client has to send the param since_created_at with the value of the last element from the response).
// first request: GET /api/products?limit=10
// second request: GET /api/products?limit=10$since_created_at:lte:2018-01-20T00:00:00
// third request: GET /api/products?limit=10$since_created_at:lte:2018-01-19T00:00:00
SELECT * FROM Users
WHERE created <= '2018-01-20T00:00:00'
ORDER BY user_id ASC
LIMIT 20
For the GraphQL query, I have found a Github repository with an example of how to implement the query with the keySet technique, but as I have mentioned earlier, this technique is rarely in used. Therefore, there are very few examples of how to implement it on the client side.
query {
users (
order_by: user_id_asc,
limit: 20,
where: { created_at: { _lte: previous_value } }
) {
id
name
created_at
}
}
Pros and Cons of KeySet-Based pagination:
👍 Pros:
- The usage of WHERE makes it more efficient than page-based pagination.
- New records are inserted on previous pages and will not cause duplication of elements.
👎 Cons
- Tight coupling of paging mechanism to filters and sorting. Forces API users to add filters even if no filters are intended.
- There is no way to jump to a specific page
- It doesn't allow sending parallel requests
- The client has to keep track of the key-value of the set
- Explosion of multiple key-param by the api
5. Seek Pagination:
An extension of KeySet paging. In seek pagination we are adding an after_id or start_id to the URL parameters. Since unique identifiers are naturally high cardinality, we remove the tight coupling between paging and filtering/sorting.
For the following request:
GET /items?limit=20&after_id=20&sort_by=email
The backend would need two queries:
- A query to get the email pivot value (O(1) lookup with hash tables) - this is the input to the second query.
SELECT email AS AFTER_EMAIL
FROM Items
WHERE item_id = 20
- Only retrieve items from the first query, whose email is after our after_email, are returned to this query. We sort by both columns, email and item_id, to ensure we have a stable sort in case two emails are the same. This is critical for lower cardinality fields.
SELECT *
FROM Items
WHERE Email >= [AFTER_EMAIL]
ORDER BY Email, item_id
LIMIT 20
Pros and Cons of Seek pagination:
👍 Pros:
- No coupling of pagination logic to filter logic.
- Consistent performance even with large offsets.
- Consistent ordering even when newer items are inserted into the table (mostly when sorting by ascending order).
👎 Cons:
- More complex for the backend to implement relative to offset based or keyset based pagination
- If items are deleted from the database, the start_id may not be a valid id.
Part 2 - Time for a Real World Example
To experiment with the pagination topic, I have built a mini-app using
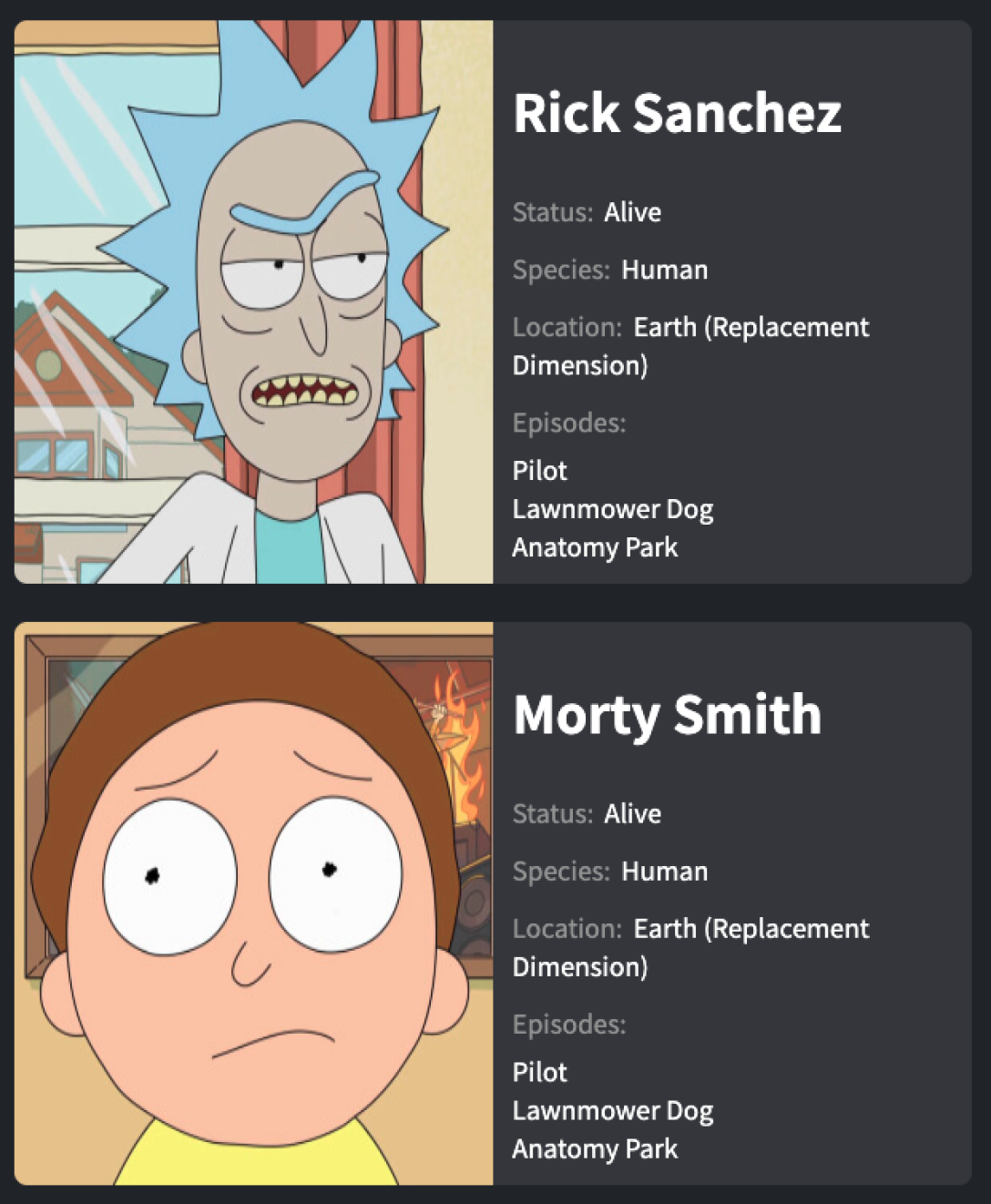
Rick and Morty APIEvery character is represented in a card that includes the character name, image, status, species, and the first 3 episodes the character appeared in.

My Rick and Morty Repository
The app was built with React.js and introduces 2 approaches to get the data:
- REST API
- GraphQL
If we look at the documentation of Rick and Morty, at the REST example, we can see that the request URL accept page param. At the GraphQL example, we can see that the query either gets a page variable. Therefore, we can conclude that Rick and Morty API was implemented with numbered-page pagination.
Now, let's take a deep breath and have a look at the REST API implementation:
import { Fragment, useEffect, useState } from 'react'
import CardDataREST from './CardDataREST'
import classes from './DataList.module.css'
const DataListREST = () => {
const baseApiEndPoint = 'https://rickandmortyapi.com/api'
const [page, setPage] = useState(1)
const [info, setInfo] = useState({})
const [results, setResults] = useState([])
const [loading, setLoading] = useState(false)
const [error, setError] = useState(null)
useEffect(() => {
setLoading(true)
fetch(`${baseApiEndPoint}/character/?page=${page}`)
.then((res) => {
if (res.status !== 200) throw new Error('Error! Something went wrong :(')
return res.json()
})
.then(({ info: resDataInfo, results: resDataResults }) => {
setInfo(resDataInfo)
setResults(resDataResults)
setError(null)
})
.catch((error) => {
setError(error)
setResults([])
})
.finally(() => setLoading(false))
}, [baseApiEndPoint, page])
const characters = results.map((character) => (
<CardDataREST key={character.id} character={character} />
))
const handleNext = () => setPage(page + 1)
const handlePrevious = () => setPage(page - 1)
if (loading) return <h3>Loading..."</h3>
if (error) return <h3>{error.message}</h3>
return (
<Fragment>
<div className={classes.dataList}>{characters}</div>
<div className={classes.btnWrapper}>
<button className={classes.loadMoreBtn} disabled={!info.prev} onClick={handlePrevious}>
Previous
</button>
<button className={classes.loadMoreBtn} disabled={!info.next} onClick={handleNext}>
Next
</button>
</div>
</Fragment>
)
}
export default DataListREST
The response from requesting all the characters, contains an object with 2 properties:
- info - an object that contains meta-data about the request
- results - array of characters
{
"info": {
"count": 671,
"pages": 34,
"next": "https://rickandmortyapi.com/api/character/?page=2",
"prev": null
},
"results": [
// ...
]
}
In the info object, we have the property next, where its value is a URL to the following page, and the URL includes a query param named page.
Info, results, and page are three params that represent the state of our application, therefore, I used the useState hook, in order to follow and control their state. Inside the useEffect hook, I have an HTTP request with the query param page, and on every successful request, I set the results and the info based on the returned data.
The page is changed by every click on next and prev (except the first time, when we don't have prev) button, and useEffect hook run again (because the page is in its dependency array).
Now, as I have mentioned, I want to show every character in a card with the character name, image, status, species, and the first three episodes of the character. All of this data, except the latter, is reachable and can be displayed right away, but the episodes that we receive from the request are in the form of an array of URLs. Therefore, To be able to display them, we must make additional requests.
import { Fragment, useEffect, useState } from 'react'
import Card from './Card'
const CardDataREST = ({ character }) => {
const [episodes, setEpisodes] = useState([])
const { episode: episodesData } = character
const firstThreeEpisodes = episodesData.slice(0, 3)
useEffect(() => {
Promise.all(
firstThreeEpisodes.map((ep) => {
return fetch(ep).then((res) => res.json())
})
).then((episodesRes) => {
setEpisodes(episodesRes)
})
}, [])
return (
<Fragment>
<Card characterRawData={character} characterEpisodes={episodes} />
</Fragment>
)
}
export default CardDataREST
In the previous block code, I mapped the results into a CardDataREST (shown above) component and passed the character as a props. In this component, I pull the episodes array out from the character object and used the useEffect hook to make requests to all the URLs in the array.
Finally, the raw character data (name, image, status, species), and the episodes' data are passed by props to a generic Card component.
import { Fragment } from 'react'
import classes from './Card.module.css'
const Card = ({ characterRawData, characterEpisodes }) => {
const { id, name, image, status, location, species } = characterRawData
const episodesToDisplay = characterEpisodes.map((episode) => (
<li key={episode.id}>{episode.name}</li>
))
return (
<Fragment>
<div key={id} className={classes.card}>
<div className={classes.cardLeft}>
<img src={image} alt={name} />
</div>
<div className={classes.cardRight}>
<h1>{name}</h1>
<p>
<span>Status:</span> {status}
</p>
<p>
<span>Species:</span> {species}
</p>
<p>
<span>Location:</span> {location.name}
</p>
<p>
<span>Episodes:</span>
</p>
<ul>{episodesToDisplay}</ul>
</div>
</div>
</Fragment>
)
}
export default Card
A nice picture of Rick and Morty, to clean up your brain before we move on to GraphQL implementation


With the knowledge we already have about the API, we build a query named getCharacters (you can name it however you want). That query receives a $page argument, and that argument's value is passed to characters - one of the queries we can use based on Rick And Morty GraphQL Documentation

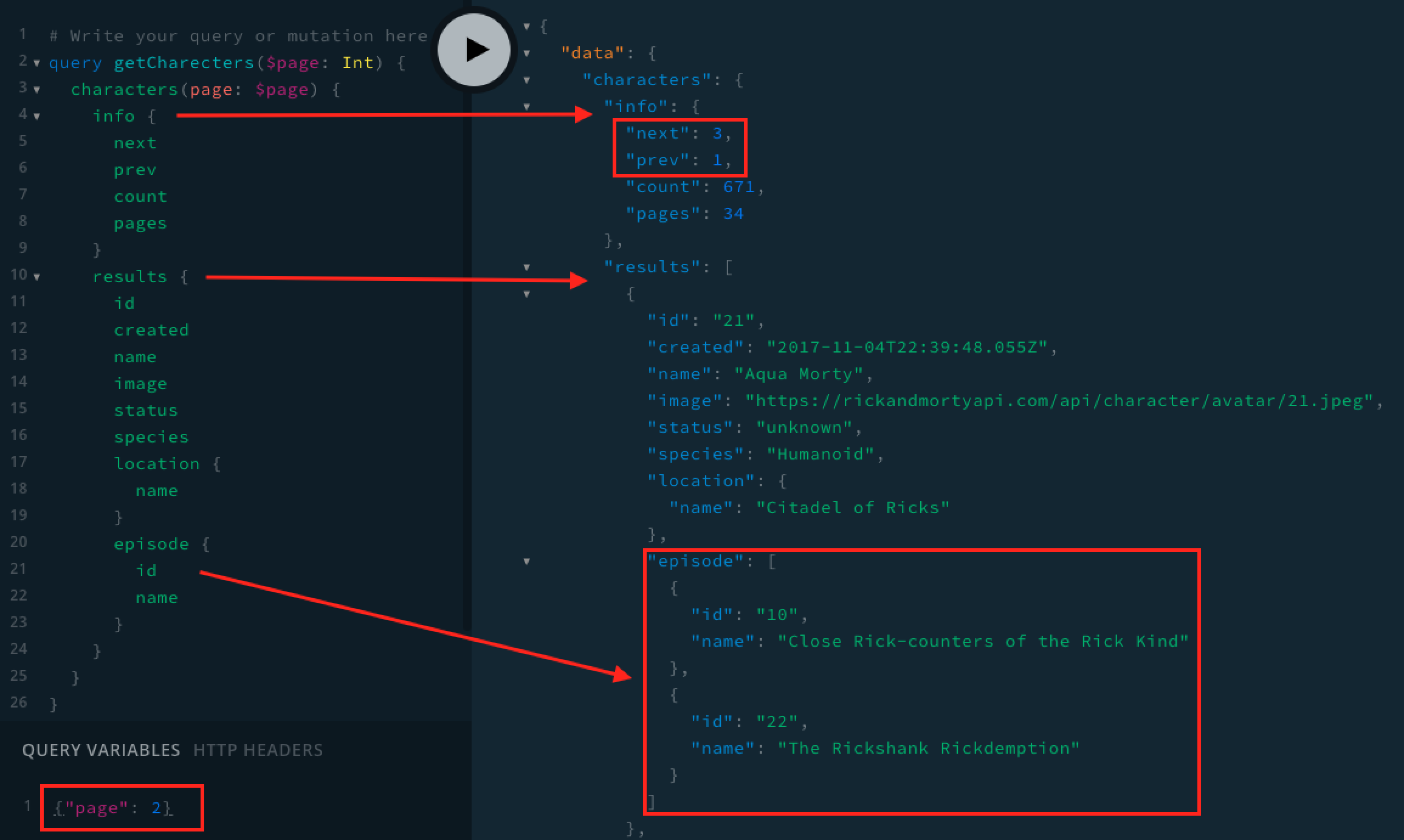
After we found our query with the help of GraphQL playground provided by Rick and Morty documentation, we can take this query to our application. Be aware that the next property of the info object is now a number that represents the next page number (and not a URL with a page query param).
import {gql} from "apollo-boost";
export const CHARACTER_QUERY = gql`
query getCharacters($page: Int!) {
characters(page: $page) {
info {
next
prev
count
pages
}
results {
id
name
image
status
species
location {
name
}
episode {
id
name
}
}
}
}
`
This query is the first argument of useQuery hook - a hook provided by Apollo Client (a state management library for JavaScript that enables you to manage both local and remote data with GraphQL). useQuery hook also receives a variable object. This object contains the variables which our query needs (in our case: page and filter, but I used the page only);
import { Fragment, useState } from 'react'
import classes from './DataList.module.css'
import { useQuery } from '@apollo/react-hooks'
import CardDataGraphQL from './CardDataGraphQL'
import { CHARACTER_QUERY } from '../graphql-queries/queries'
const DataListGQL = () => {
const [page, setPage] = useState(1)
const { loading, error, data, fetchMore } = useQuery(CHARACTER_QUERY, {
variables: {
page: page,
},
notifyOnNetworkStatusChange: true,
fetchPolicy: 'cache-and-network',
})
const handlePage = (isNext) =>
fetchMore({
variables: {
page: page,
},
updateQuery: (prev, { fetchMoreResult }) => {
if (!fetchMoreResult) return prev
return Object.assign({}, prev, {
characters: { ...prev.characters, ...fetchMoreResult.characters },
})
},
}).then(() => {
const pageNumber = isNext ? page + 1 : page - 1
setPage(pageNumber)
})
const characters = data?.characters.results.map((character) => {
return <CardDataGraphQL key={character.id} character={character} />
})
if (loading) return <h3>Loading...</h3>
if (error) return <h3>{error.message}</h3>
return (
<Fragment>
<div className={classes.dataList}>{characters}</div>
<div className={classes.btnWrapper}>
<button
className={classes.loadMoreBtn}
onClick={() => handlePage(false)}
disabled={!data.characters.info.prev}
>
Previous
</button>
<button
className={classes.loadMoreBtn}
onClick={() => handlePage(true)}
disabled={!data.characters.info.next}
>
Next
</button>
</div>
</Fragment>
)
}
export default DataListGQL
useQuery returns 4 parameters: loading, error, data and fetchMore. Data is the results we are getting back from the request, and fetchMore is a function that gets the variable object (in our case, with page property), and a function called updateQuery().
updateQuery()'s purpose is to update the query based on the change in the variable(s). This change happens when we click on the previous or the next button, by setting a new state to the page.
The results are mapped to CardDataGraphQL although this time we don't really need this layer, as the episodes array is returned as an array of objects with the episode id and the episode name. I decided to build this component for the sake of consistency. The results are split into raw character data (name, image, status and species), and episodes data that get sliced to get the first 3 episodes.
import { Fragment } from 'react'
import Card from './Card'
const CardDataGraphQL = ({ character }) => {
const { episode: episodesData } = character
const firstThreeEpisodes = episodesData.slice(0, 3)
return (
<Fragment>
<Card characterRawData={character} characterEpisodes={firstThreeEpisodes} />
</Fragment>
)
}
export default CardDataGraphQL
To conclude, there is no question about how simple it is to make a request and get the exact desired data with a GraphQL query.
I have found a picture that illustrates this very nicely, and I will end this post with that picture, and without diving into pros, cons, and performance issues (although it is very important, this is not the purpose of this post).


Thanks for reading, hope you learned something new and that you liked my little example app with Rick and Morty.