
- Published on
Big Words in Javascript - Part 1
- Authors
- Name
- Amit Barletz
- @BarletzA52


Making some scary words in JavaScript less scary
Let's start with defining what JavaScript is in a few simple words:
'Javascript is a high-level, prototype-based object-oriented, multi-paradigm, interpreted or just in time compiled, dynamic, single-threaded, garbage-collected programming language with first class functions and non-blocking event loop concurrency model.' 🧐
Ok, some of these words do not sound very simple, but in this series of articles I will, hopefully, make them simpler and less scary.


Therefore, I decided to separate it into 3 parts.
Diving into part 1:
This part is going to cover a lot of concepts, so hang on ✊
High-level programming language
When it comes to high-level programming languages, and on the other side - low-level programming languages, the key concept is the level of abstraction.
High-level programming languages provides a strong abstraction from machine instructions. It is reflected by the ability to use natural language elements, and it may automate significant functions of the computing system. Therefore, it is easier to use and more human readable.
Interpreted or JIT compiler
Actually, I should begin with a reservation.
Compilers are a part of the JavaScript engines, like V8 for Chrome and Spider-Monkey for Firefox. The JavaScript engine is a very complex topic (which may even deserve a series of articles of its own). Therefore, I am about to explain what the terms interpreted and compiler mean in a very abstract, high-level manner 😏.
There are generally two ways of translating our code to machine code:
- Interpreter - translate and read the file line by line on the fly.
function calc(x, y) {
return x + y
}
for (let i = 0; i < 1000; i++) {
calc(1, 2)
}
- Compiler - work ahead of time to create a translation of the code we have just written, and compile it to machine code.
In the example code block above, the compiler will make one pass through the code and try to understand what the code does. Then it will rewrite the code in a new language which gets interpreted and gives the same result as the original code.


Wait, what?! Didn't you just say that there are 2 ways of translating our code to machine language? How come compilation also has an interpreted phase?
The answer is that in some respects, most languages have to be interpreted and compiled. There are times in which we might prefer that our code is compiled, and there are times we want it to be interpreted. The JIT compiler is a combination between compiler and interpreter and it decides which method (interpretation or compilation) to use for our code.
Let's explain it by using an example.
In some way, interpreters are faster than compilers because they start to work earlier and there is no compilation step. On the other hand, the lack of a compilation step leads to a situation in which, like in our example, the for loop runs the same code 1000 times and always gives us the same result, and that's when it can get slow.
The compiler actually helps us here, because when it identifies code like this, which runs many times with the same input and always returns the same output:
for (let i = 0; i < 1000; i++) {
calc(1, 2)
}
It can simplify the code to something like this:
for (let i = 0; i < 1000; i++) {
3 // 1 + 2
}
Just-in-time compilation (JIT) is a method for improving the performance of interpreted programs. During execution, the program may be compiled into native code to improve its performance.
This process also known as dynamic compilation - the runtime environment can profile the application while it is being run (optimized code). If the behavior of the application changes while it is running, the runtime environment can recompile the code.
Some of the disadvantages include startup delays and the overhead of compilation during runtime. To limit the overhead, many JIT compilers only compile the code paths that are frequently used.
Dynamic programming language
In dynamic programming languages, some operations that are done during compile time, can also be done at runtime. In other words, it is possible to change the type of a variable or add new properties/methods to an object while the program is running.
This is opposed to static programming languages, in which such changes are normally not possible.


Another JavaScript related term that we frequently hear about is that it is a weakly-typed programming languages, meaning we do not have to define our variables with their types. On the other hand, there are strongly-type programming languages (like Java, TypeScript) which force you to define your variables types, and you cannot change the type of a variable.
let name = 'amit'
console.log(name) // amit
name = 5
console.log(name) // 5
let name = 'amit'
console.log(name)
name = 5 // Assigned expression type 5 is not assignable to type string
console.log(name)
Garbage collected language
When it comes to memory management in JavaScript we can, in some ways, ignore the stack. The stack is a short living memory. It gets cleaned Automatically when items are popped out of it.
The heap is a long living memory and has to be managed, otherwise, it might overflow at some point. Fortunately, in JavaScript, we don't need to actively manage memory (unless we are building super complex application), although as JavaScript developers, we should understand the language's memory management.
The garbage collector in Chrome (V8) periodically checks the heap for unused objects (objects without references), and remove those objects.
let person = { name: 'Linda' }
In the example above, as long as 'person' variable points to the object (which is a referenced type, therefore it is stored on the heap), the JavaScript engine (which contains the garbage collector) knows that we have a reference to that object and doesn't remove it from memory.
As soon as we do something like
person = null
The object is no longer referenced and gets cleaned up.

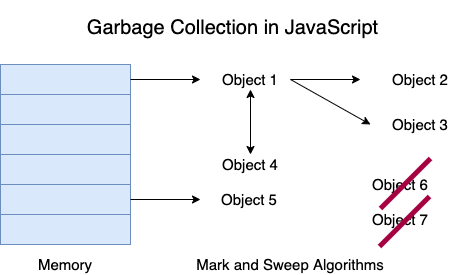
The garbage collector uses the mark and sweep algorithm.
In the diagram above, we can see that object 1 and object 5 are saved in memory, object 1 points to objects 2, 3 and 4. The garbage collector marks all the objects that are referenced (either directly, or by another referenced object) and sweeps the objects which aren't referenced. In this case, since there is no object referencing objects 6 and 7, they will be swept.
On modern browsers (engines), arrays and objects created with let or const, can be cleaned up if don't use them anymore in our code.
But, Beware of "Memory Leaks". Memory leaks can occur when references to unused objects aren't terminated.
First class function && Higher order functions
These two terms are closely related, as it’s hard to imagine a language with first-class functions that would not also support higher-order functions, and vice versa.
Higher order function is a function that can receive a function as a parameter, or a function that returns another function.
First class functions are functions that:
- Can be assigned to variables and properties of objects (method)
const func = function () {}
- Can be passed as an argument to another function
function a(fn) {
fn()
}
a(function () {
console.log('Hi')
})
Function 'a' is a higher order function because it takes function 'fn' as an parameter.
- Can be returned as a value from other functions
function b() {
return function c() {
console.log('Hello')
}
}
b() // [function: c]
// or
b()() // Hello
// or
const d = b()
d() // Hello
Function 'b' is also a higher order function because it returns function 'c'.
Why and how higher order functions are so important in JavaScript?
Let's take a look at the following example:
function loginTarzan() {
let arr = []
for (let i = 0; i < 100000; i++) {
arr.push(i)
}
return 'Hi Tarzan'
}
loginTarzan() // Hi Tarzan
function loginAladdin() {
let arr = []
for (let i = 0; i < 100000; i++) {
arr.push(i)
}
return 'Hi Aladdin'
}
loginAladdin() // Hi Aladdin
'loginTarzan' and 'loginAladdin' are two functions that do the same thing. The problem with them is that this violates a famous programming principle - DRY - Do Not Repeat Yourself.
In order to fix this problem we can rewrite the function so that it takes the login user as an argument:
function loginUser(userName) {
let arr = []
for (let i = 0; i < 100000; i++) {
arr.push(i)
}
return `Hi ${userName}`
}
loginUser('Mufasa') // Hi Mufasa
But since we are trying to learn about higher order functions here, let's take it another step forward.
function authenticate(verify) {
let arr = []
for (let i = 0; i < verify; i++) {
arr.push(i)
}
return true
}
const greetLoggedInPerson = (name) => `Hi ${name}`
function loginPerson(person, fn) {
if (person.level === 'admin') {
fn(30000)
} else if (person.level === 'user') {
fn(10000)
}
return greetLoggedInPerson(person.name)
}
loginPerson({ name: 'Simba', level: 'admin' }, authenticate) // Hi Simba
First, we can separate the logic of the user login from the greeting logic so that the 'loginPerson' function returns the 'greetLoggedInPerson' function.
Second, let's assume that in addition to the regular user, we also have an admin user which needs more complex and time-consuming authentication.
With that, in addition to sticking to DRY and writing generic functions, we can now both pass the data to the function, and define what to do with that data (authenticate).
person: {name: 'Simba', level: 'admin'}
Almost there...
The following segment does not mention the JavaScript definition written in the beginning of this blog post, but I decided to include it in this part because I think that it also touches one of the "big words" in JavaScript and has some connection with the previous topic (First class function && Higher order functions).


Function expression VS Function declaration
In JavaScript, there are different ways of writing functions:
Function Declaration - “saved for later use” and will be executed later, when it is invoked. Also called function statement. To declare such a function we defined it with the 'function' keyword and then the name of the function.
function calcRectArea(width, height) {
return width * height
}
console.log(calcRectArea(5, 6)) // 30
Function Expression - function which is stored in a variable. The function doesn't have a name (anonymous), and is always invoked using the variable name.
const calcRectArea = function (width, height) {
return width * height
}
console.log(calcRectArea(5, 6)) // 30
Besides naming, there are at least 3 more important differences between function declarations and function expressions:
1. Passed as an argument to another function
In JavaScript, we can pass to a function, another function as an argument (first class function, callback). The most common way (the convention) is to pass a function expression as an argument to another function.
let array = [1, 3, 5, 8, 9]
const mapAction = function (item) {
console.log(item * 10)
}
array.map(mapAction) // 10 30 50 80 90
If we do it with a function declaration, the 'mapAction' function will be available to the entire application, and since we want it as a callback - there is no need for that. If that callback is a function expression (like in the example above), it will not be available outside of the function that uses it.
let array = [1, 3, 5, 8, 9]
function mapAction(item) {
console.log(item * 10)
}
array.map(mapAction) // 10 30 50 80 90
2. Hoisting
Hoisting is the behaviour of moving the variables or function declarations to the top of their respective environment during compilation phase. (OK, not actually moving, but bear with me for now, and soon it will all be clear). Variables are partially hoisted, and functions declarations are hoisted.
sayHi1()
console.log(name) // undefined
function sayHi1() {
console.log('Hi') // Hi
}
var name = 'Amit'
console.log(sayHi2) // undefined
sayHi2() // Uncaught TypeError: sayHi2 is not a function
var sayHi2 = function () {
console.log('Hi')
}
In the code example above, we can see that with function declarations, we can call the function 'sayHi1 even before the Javascript engine reads that function. On the other hand, in the 'sayHi2 function, we got 'Uncaught TypeError: sayHi2 is not a function'.
During the creation phase the Javascript engine is looking through the code and as soon as it sees the 'var' or 'function' keyword - it allocates memory for the variables and the functions. The variables are initialized with the value of 'undefined' (partially hoisted), and function declarations are fully hoisted - that's why we can call the function even before they are actually declared.
That's what I was meant earlier, when I said that the variables and functions are moved to the top.
Now It is more clear why we got an error in 'sayHi2 function. 'sayHi2 is a variable which partially hoisted and during the creation phase, initialized to undefined, and undefined is clearly not a function 🙃
NOTE: hoisting happens on every execution context (during the creation phase). In the following example 'favouriteSport' on the global execution context has a different value from 'favouriteSport' in 'choseFavouriteSport' variable. Therefore, when we log the 'Original favourite sport' it is undefined (remember? variables and functions are moved to the top of their respective environment)
var favouriteSport = 'running'
var choseFavouriteSport = function () {
console.log('Original favourite sport: ' + favouriteSport) // Original favourite sports: undefined
var favouriteSport = 'HIIT'
console.log('New favourite sport: ' + favouriteSport)
}
choseFavouriteSport()
There are arguments whether we should use hoisting as it has an unpredictable behaviour and maybe even it is a bad practice.
By using const and let, we can resolve that issue, but be aware even if we change the 'var' to 'const', technically there is still hoisting happening. That is why you get a reference error instead of looking at the global 'favouriteSport' variable. let and const hoist, but you cannot access them before the actual declaration is evaluated at runtime. The Javascript engine knows about the 'favouriteSport' variable, but does not provide us access to it.
3. IIFE - Immediately Invoked Function Expression
As the name may imply, IIFE is a function which is called right after it is defined. The first thing that IIFE comes to resolve is the problem with the global variables (before the ES-Modules in ES6). An IIFE is a function expression which wrapped with braces and in the end - immediately invoked: ().
It implements a design pattern used by a lot of libraries (like jQuery) to make a local scope, so that we can avoid namespace collision.
sayHi1()
;(function sayHi1() {
console.log('Hi')
})()
The Javascript engine does not recognize the 'sayHi1' function as a function declaration, as the first thing it sees is not the 'function' keyword, but the '('. Therefore, it considers it as a function expression which not assigned to any variable (no global property is created).
All the variables and functions created inside an IIFE are scoped in it, so they cannot be reached from the outside, unless there are properties which we decided to expose (like jQuery expose the jQuery object, or the $ sign).
finishing 🙌
That is it for this part. Thanks for reading, take care, get some rest and be prepared, because in the next part I am gonna talk about JavaScript as a single threaded programming language and of course - the event loop.

