
- Published on
Big Words in Javascript - Part 2
- Authors
- Name
- Amit Barletz
- @BarletzA52


Single Threaded, Non-Blocking, Asynchronous, Concurrent Language - huh?! 😵
A continuation of the previous blog post Big Words - Part 1.
In this part, I will explain the statement that JavaScript is a single-threaded, non-blocking, asynchronous, concurrent language.
As a self-taught programmer, when I had first encountered that statement, the first question I asked was:
'WHAT IS A THREAD?'
Thread in computer science is the execution of running multiple tasks or programs at the same time. Each unit capable of executing code is called a thread.
In JavaScript, we only have one thread - the main thread. That thread is used by the browser to handle user events, render and paint the display, and to run the majority of the code that comprises a typical web page or app.
Say what?!
If JavaScript can run only one instruction at a time, it should be synchronous, because "synchronous" means a bunch of commands in sequence. How can JavaScript be asynchronous and single-threaded at the same time?


The JavaScript Runtime (in the browser):
The JavaScript runtime is a container that includes all the pieces that are necessary to execute JavaScript code. The main part of the JavaScript runtime is the engine, and it has a single call stack and a single memory heap.
A call stack is a data structure that records where we are in the program and which execution context is currently active. As a continuous region of memory, primitive types are stored in the call stack, in the execution context in which they were declared.
Object literals, arrays, and functions are stored in the heap, which is a much larger region.
Another part of the JavaScript runtime is the Web APIs, which contain the HTTP requests (fetch), timers, DOM, events, etc. (they are NOT part of the JavaScript language).
The next part of the JavaScript runtime is the callback queue. This is a data structure that holds all the 'ready to be executed callback functions, which are attached to some events that have occurred.

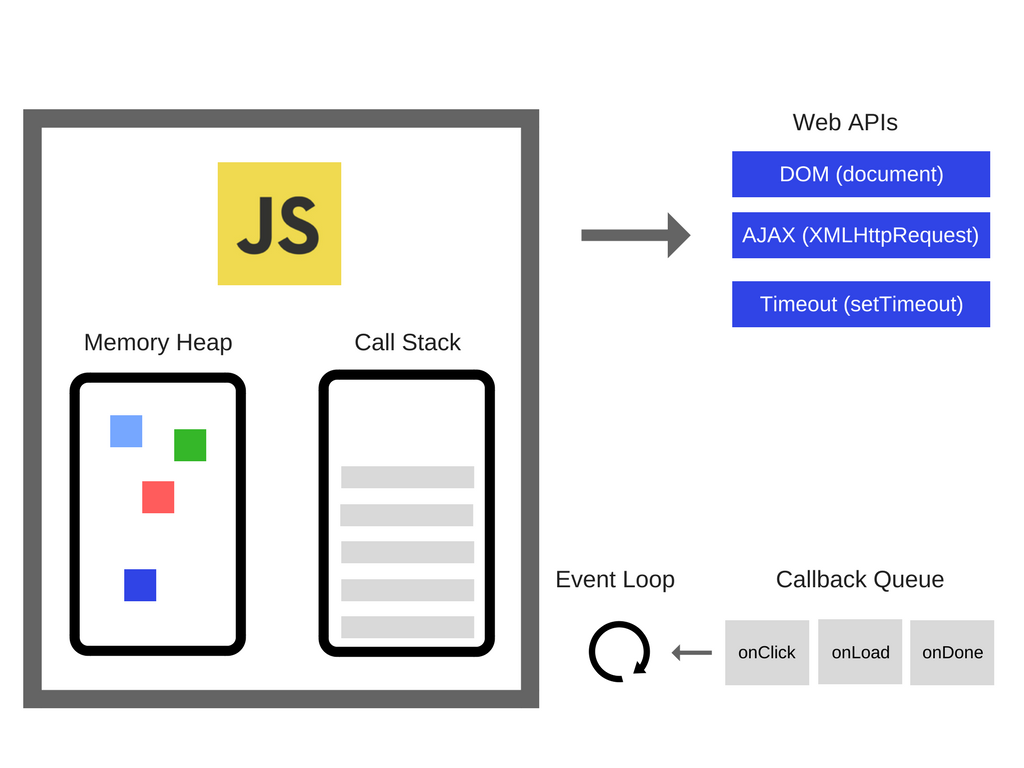
The event loop's job is to check if the call stack is empty, and if so, it takes the callbacks from the callback queue and put them in the call stack, so that they can be executed. Therefore, the event loop is an essential part of making asynchronous behavior possible in JavaScript. It is the reason why we can have a non-blocking concurrency model in JavaScript.
concurrency model is when two or more tasks can start, run, and complete in overlapping periods.
Parallelism is when tasks run at the same time on a multicore processor, for instance - web workers: a JavaScript program which running on a different thread, alongside the main thread.
A Deep Look at How It Works Behind The Scenes:
Let's have a look at the following code.
What do you think the output of this code will be?
console.log('1')
setTimeout(() => console.log('2'), 2000)
console.log('3')
The answer is '1', then '3' and in the end, after two seconds '2'.
JavaScript code is read line by line. The first line of code: 'console.log('1');' is pushed to the call stack, and when the call stack is empty (meaning there is nothing excluding that line of code, and it is at the top of the stack), it is executed and popped off the stack printing '1' to the console.
Then 'setTimeout' is pushed to the call stack, but it is a process that takes time and can block the call stack. In addition, 'setTimeout' is NOT part of the JavaScript core language, but a part of the web API. Therefore, 'setTimeout' notifies the Web API that there is a timer that has to be started.
The next line of code: 'console.log('3');' is pushed to the call stack, and again, as nothing is excluding that line of code, and it is on the top of the stack, it is executed, popped off the stack and prints '3' to the console.
When the Web API is done with 'setTimeout', it pushes the callback to the callback queue (the callback of 'setTimeout' is the code after the fat arrow). Then comes the important part of the event loop.
The event loop checks again and again if the call stack is empty. If so, it checks if there are any callbacks in the callback queue, and if there are, it pushes the first callback from the queue to the call stack. Then the code is executed, popped off the stack and prints '2' to the console.


Now, to the famous interview question:
what do you think will happen if we change 'setTimeout' to zero seconds?
setTimeout(() => console.log('2'), 0)
It still gives us the same output because even though it zero seconds, it still went through the process.
Every piece of code that is a part of the Web API, went through the same process explained above. In other words, if we had a DOM event, 'fetch' or 'AJAX' request instead of (or in addition to) 'setTimeout', it would have to go through the process of
Web API → callback queue → event loop → call stack
Spoiler Alert! - Now it is No longer accurate
What do you think will be the output of the following code?
console.log('1')
setTimeout(() => console.log('2'), 1500)
fetch('https://api.jsonapi.co/rest/v1/user/list')
.then((response) => response.json())
.then((responseJSON) => console.log(responseJSON.data.users))
console.log('3')
There is an interesting thing about the code example above.
The output of the code above is 1, 3, the list of users and 2. The user's list response from the JSON API is printed before the timer, even though it may take more than 1500ms to return the response.
Inside 'fetch()' we have '.then()', which is basically a callback, but it is a callback related to Promises. Callbacks of promises are not going to the callback queue, instead, it has a special queue called microtasks queue, which has a priority over the callback queue.
How does it happen?
After a callback has been taken from the callback queue, the event loop will check if there are any callbacks in the microtasks queue, and if there are, the event loop will run all the microtasks queue callbacks before it runs any more callbacks from the callback queue. Moreover, if one microtask adds a new microtask, then that new microtask is also executed before any callbacks from the callback queue.
That's why the duration we defined fro 'Timers' ('setTimeout', which is sent to the callback queue) is not guaranteed, the only guarantee is that the timer will not run before the time we had defined, but it might run after that time. It all depends on the state of the callback queue (also called Macrotask), and the microtasks queue.
Promises are pretty new in JavaScript (natively) and to accommodate this new addition, the event loop had to change. The change was the addition of another queue, higher priority, for the promises callbacks - microtasks queue (also called the job queue).
So, with that knowledge, can you guess what will be the output of the following code? (answer is at the end of this post 🤫).
setTimeout(() => console.log('1'), 0)
setTimeout(() => console.log('2'), 1000)
Promise.resolve('ho').then((data) => console.log('hi', data))
console.log('3')
Thanks for reading, that was a pretty short blog post, relatively to the others. I hope it was short, concise but illuminating.
In the next and last blog post of this series, I will write about JavaScript as a multi-paradigm, prototype-based object-oriented, functional programming language.
And of course, it isn't a good blog post about the event loop without referencing Philip Roberts's talk:
What the heck is the event loop anyway?
https://www.youtube.com/watch?v=8aGhZQkoFbQ
There are 2 other talks, more recent and updated (microtasks queue), which I recommend watching:
Further Adventures of the Event Loop - Erin Zimmer
https://www.youtube.com/watch?v=u1kqx6AenYw&t=3s
In The Loop - Jake Archibald:
https://www.youtube.com/watch?v=cCOL7MC4Pl0
By the way, the output of the code above would be 3, hi ho, 1, 2.